Python application to export data to IBM cloud object storage
Published On: 2021/07/05
In this article I would like to take you through the steps to create a small POC which involves IBM Object storage, MongoDB and IBM Functions. This article explains a part of the POC which reads the records from MongoDB, prepares a file and then sends it to IBM Object storage.
Dependencies
I have used the pymongo library for the MongoDB operations and ibm-cos-sdk library to push the generated files to IBM Object storage.
pymongo == 3.11.4
ibm-cos-sdk == 2.10.0
Config
The below given configuration details are required to connect the application to IBM cloud object storage. We could find the values under the Service credentials section of object storage.
Path to Service Credentials: Resource List -> Storage -> Click on your cloud storage object -> Click on Service credentials side menu -> Expand your bucket.
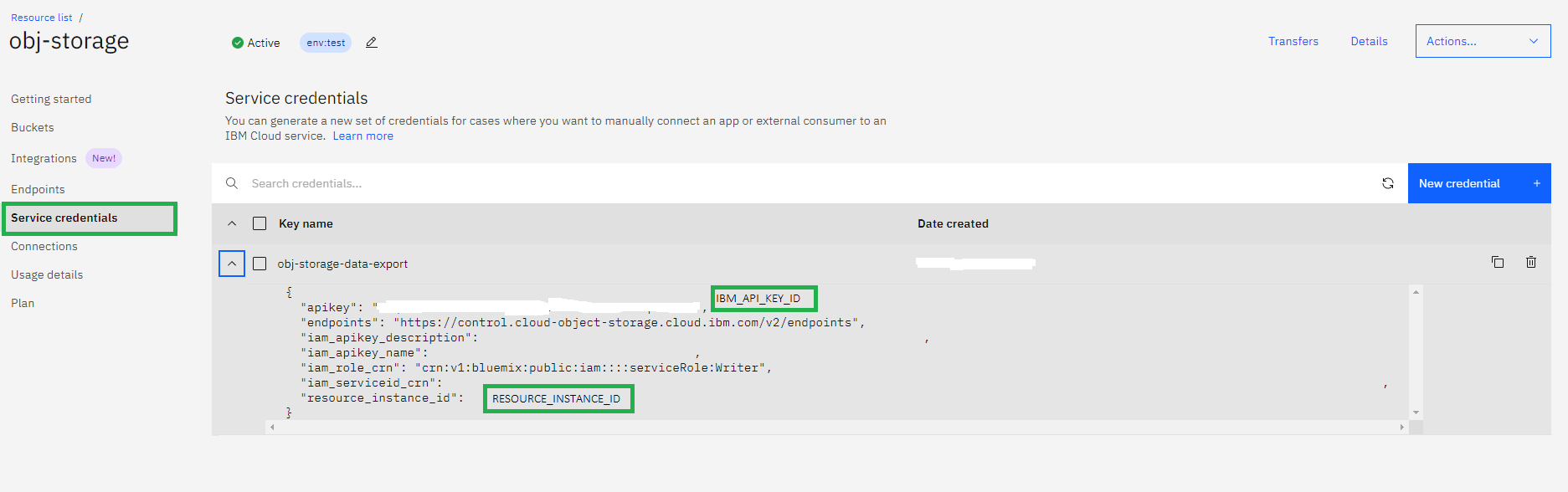
ibm_credentials = {
'IBM_API_KEY_ID': os.environ.get('IBM_API_KEY_ID', 'XgqhTANhFJxlM6E2JRRJsxwlC7wDKJKrugA-Cqu9sXA8'),
'IAM_AUTH_ENDPOINT': os.environ.get('IAM_AUTH_ENDPOINT', 'https://iam.cloud.ibm.com/identity/token'),
'RESOURCE_INSTANCE_ID': os.environ.get('RESOURCE_INSTANCE_ID', 'crn:v1:bluemix:public:cloud-object-storage:global:b/d874c2dcbb1646a9a548439f6195313a:55a2daca-7fec-4c63-8757-a2e9596af3ba::'),
'ENDPOINT': os.environ.get('ENDPOINT', 'https://s3.us-xx.cloud-object-storage.appdomain.cloud'),
'BUCKET': os.environ.get('BUCKET', 'obj-storage-data-export'),
}
The below given configuration is the local MongoDB connection configuration.
mongo_config = {
'DB_URL' : os.environ.get('DB_URL', "mongodb://%s:%s@localhost:27017/?authSource=%s"),
'DB_SRV_USER' : os.environ.get('DB_SRV_USER', "testAdmin") ,
'DB_SRV_PASSWORD' : os.environ.get('DB_SRV_PASSWORD', "test123"),
'DB_SRV_AUTHSOURCE' : os.environ.get('DB_SRV_AUTHSOURCE', "admin")
}
Connect to MongoDB
As a first step to fetch the data from mongodb, use the MonoClient of pymongo to connect to the mongodb instance.
dbUrl = db_credentials['DB_URL']
username = db_credentials['DB_SRV_USER']
password = db_credentials['DB_SRV_PASSWORD']
authSource = db_credentials['DB_SRV_AUTHSOURCE']
client = MongoClient(dbUrl % (username, password,authSource))
db = client['testdb']
coll = db['credit_assessments']
Export-File Builder
In the below code, we are trying to fetch the customers with high risk level from the collection credit_assessments of testdb with high risk level. A projection is used to fetch only the required fields from the stored record. If there is an error while reading or writing to the file the StatusUpdater object will invoke another cloud function to store the job status.
def build_file(self, file_name):
try:
cursor = coll.find({"assessmentResult.riskLevel":"HR"}, { 'customerId':1, 'federation':2, 'tenant':3, 'assessmentDate':4, 'assessmentResult.riskLevel': 5, 'assessmentResult.score': 6 }).batch_size(10000)
self.write_to_file(cursor,file_name)
cursor.close()
return True
except (PyMongoError, IOError) as err:
print("Error: {0}".format(err))
cursor.close()
StatusUpdater().update_export_status('FAILED')
return False
After reading the data, it has to be written to a file and stored to the associated persistent volume. We use IBM block storage to store this temporary file and then later move it to the cloud object storage.
def write_to_file(self, cursor,file_name):
fileName = file_storage+"/"+file_name
try:
with open(fileName, 'w') as f:
for rec in cursor:
s = rec['kycFileId']+'|'+rec['federation']+'|'+rec['tenant']+'|'+rec['assessmentDate']+'|'+rec['assessmentResult']['riskLevel']+'|'+str(rec['assessmentResult']['totalScore'])+'\n'
f.write(s)
except IOError as err:
raise err
Export File to Object Storage
Next is to upload the file to the object store. For this, we could use the ibm_boto3 client for s3 service. ibm_boto3 is AWS boto3 client forked for IBM cloud operations. Invoke the status update cloud function once the upload is completed to register the completion status of the job.
def export_file(self,file_name):
export_folder = "assessments/user-exports/"
try:
cos = ibm_boto3.client(service_name='s3',
ibm_api_key_id=s3_credentials['IBM_API_KEY_ID'],
ibm_auth_endpoint=s3_credentials['IAM_AUTH_ENDPOINT'],
config=Config(signature_version='oauth'),
ibm_service_instance_id=s3_credentials['RESOURCE_INSTANCE_ID'],
endpoint_url=s3_credentials['ENDPOINT'])
cos.upload_file(Filename=file_storage+"/"+file_name,Bucket=s3_credentials['BUCKET'],Key=export_folder+file_name)
except Exception as e:
print(Exception, e)
else:
print('File Uploaded')
StatusUpdater().update_export_status('SUCCESS')
return True
Clear the exported file
As we have written the file to a temporary block storage area, remove it once the upload operation is completed.
def clear_file(self,file_name):
os.remove(file_storage+"/"+file_name)
print('cleaned '+file_name)
Run Main
The main method calls the following operations
- Create filename
- Generate the export-file
- Export the file to object storage
- Clean the uploaded file
| |
Conclusion
In this article, we have gone through the steps to connect a python application to the IBM cloud object storage using the service credentials associate with the storage bucket.